



Salutations, chers lecteurs ! Permettez-moi de vous présenter le monde de la technologie innovante « reconnaissance vocale à partir d’un fichier audio ». Cet outil progressif a un impact profond sur de nombreux aspects de nos vies, de l’optimisation des processus d’affaires à l’amélioration des tâches quotidiennes.
Vous êtes-vous déjà demandé à quelle vitesse nous sommes passés de la parole parlée à sa visualisation sous forme de texte ? Dans cette revue, nous plongerons ensemble dans l’histoire de la reconnaissance vocale fichier audio. Découvertes, percées technologiques, tout cela vous attend.
Vous apprendrez comment cette technologie fonctionne. Le concept de « transcription audio en texte » vous deviendra familier. Nous discuterons de son application pratique et de ses avantages.
Ensemble, nous examinerons comment la reconnaissance vocale fichier audio a transformé les processus d’affaires. Nous découvrirons comment cet outil simplifie notre vie quotidienne.
Comment choisir les meilleurs programmes pour la reconnaissance vocale à partir d’un fichier audio ? Nous vous conseillerons ! Jetons un coup d’œil aux meilleurs services en ligne et fournissions des conseils utiles.
Et bien sûr, nous n’oublierons pas de regarder vers l’avenir. Quelles innovations nous attendent dans le domaine de la reconnaissance vocale fichier audio ? Que prédisent les experts ?
Préparez-vous pour un voyage passionnant. Ouvrons de nouveaux horizons dans la reconnaissance vocale à partir d’un fichier audio !
Introduction à SpeechFlow, un outil de traduction en ligne de l’audio au texte
Avant de commencer, j’aimerais vous présenter un logiciel qui a révolutionné l’industrie de la reconnaissance vocale : SpeechFlow.
SpeechFlow est un programme en ligne de reconnaissance vocale à partir d’un fichier audio conçu pour les organisations et les individus souhaitant améliorer leur travail en ligne, les téléconférences, le service à la clientèle, et bien plus encore. Avec SpeechFlow, vous pouvez facilement convertir la voix en texte et effectuer sans effort la reconnaissance vocale. SpeechFlow offre un certain nombre d’avantages incroyables, notamment :
- Services de transcription multilingues : SpeechFlow prend en charge les services de transcription dans 14 langues. Il est important de noter que notre précision est supérieure à celle de nos pairs dans toutes les langues, pas seulement en anglais.
- Texte précis et lisible : Le modèle IA de SpeechFlow crée des transcriptions faciles à lire et à comprendre, avec une ponctuation appropriée et une lisibilité optimisée.
- Traitement rapide : SpeechFlow peut traiter jusqu’à 1 heure d’audio en moins de 3 minutes, offrant une solution rapide et efficace pour les entreprises et les particuliers.
- 5 heures d’essai gratuit : SpeechFlow offre une période d’essai gratuit de 5 heures, alors que de nombreux outils ne proposent pas d’essais gratuits ou ne les proposent que pour une durée limitée.
- Tarification rentable : SpeechFlow utilise un modèle de tarification « pay-as-you-go » qui est facturé à seulement 0,0002 $ par seconde. Il offre des services de haute qualité à un coût inférieur, tout en fournissant aux utilisateurs un contrôle total et une transparence sur leur utilisation et leurs dépenses.
Si vous cherchez un convertisseur de voix en texte, un convertisseur d’audio en texte, ou un outil de reconnaissance vocale, SpeechFlow est votre choix idéal. Essayez SpeechFlow aujourd’hui et simplifiez la tâche de la reconnaissance vocale à partir d’un fichier audio.
Aperçu historique : Le début de la traduction audio en texte et son évolution
Les systèmes de reconnaissance vocale à partir d’un fichier audio sont devenus largement disponibles grâce à une longue histoire de développements et d’innovations. Comme le souligne IEEE Spectrum, les premières expériences dans le domaine de la reconnaissance vocale ont commencé dès les années 1950. Mais à cette époque, il s’agissait des systèmes les plus simples. Ils ne pouvaient reconnaître que des mots individuels dans un contexte très limité.
Les progrès dans ce domaine ont été liés au développement des technologies numériques. À partir des années 1970, lorsque l’apprentissage automatique a commencé à être largement utilisé dans la recherche, la reconnaissance vocale fichier audio est devenue possible. Selon un article paru dans Nature, c’est pendant cette période que les fondements de nombreuses méthodes modernes de reconnaissance vocale ont été développés, y compris les modèles de Markov cachés et les réseaux neuronaux.
Dans les années 1990, lorsque les ordinateurs sont devenus plus accessibles, les systèmes de reconnaissance vocale ont commencé à apparaître dans des produits commerciaux. Les utilisateurs et les organisations pouvaient appliquer ces technologies dans leur travail.
Le début des années 2000 a apporté une nouvelle vague de développement dans le domaine de la reconnaissance vocale. Comme le prétend Forbes, c’est à cette époque que le travail actif a commencé sur la création de systèmes capables de comprendre non seulement des mots individuels, mais des phrases et des sentences entières.
Aujourd’hui, la reconnaissance vocale à partir d’un fichier audio est devenue un outil puissant qui change notre vie. Elle a démocratisé l’accès à l’information et facilité la communication. Tout cela a été rendu possible grâce aux efforts des chercheurs, ingénieurs et développeurs du monde entier.
À l’avenir, cette technologie continuera à évoluer. Elle simplifiera encore plus notre vie quotidienne et notre travail.
Fondamentaux de la technologie : Comprendre comment fonctionne la traduction audio en texte
La technologie de reconnaissance vocale à partir d’un fichier audio est basée sur un ensemble complexe d’algorithmes et de modèles d’apprentissage automatique. Explorons en détail comment cela fonctionne.
La première étape est la modélisation acoustique. Durant ce processus, le signal audio est converti en forme numérique, créant un spectrogramme, une représentation visuelle du son. Le système divise ensuite ce spectrogramme en segments courts et superposés appelés trames. Cela aide le système à reconnaître les sons individuels, ou phonèmes, dans la parole.
L’étape suivante est la reconnaissance vocale. Ici, un modèle d’apprentissage automatique, souvent appelé « modèle acoustique », est utilisé pour associer chaque trame à un phonème spécifique. C’est un processus complexe, car différentes personnes prononcent les mêmes phonèmes différemment. Grâce à de grands volumes de données d’entraînement, les systèmes peuvent gérer ces accents et styles de parole diversifiés.
La troisième étape est la modélisation lexicale. Ce processus lie les phonèmes reconnus en mots et en phrases, en utilisant un « modèle de langue ». Le modèle de langue comprend la grammaire et le contexte général de la langue, lui permettant de prédire quels mots sont les plus susceptibles de suivre d’autres.
L’étape finale est la sortie du texte reconnu. À ce stade, le système vérifie ses prédictions et les corrige si nécessaire pour fournir le texte le plus précis et compréhensible.
Comprendre ces bases vous aidera à mieux comprendre comment et pourquoi les systèmes de reconnaissance vocale fichier audio fonctionnent comme ils le font. Cela vous aidera également à faire un choix plus éclairé lors de la sélection d’un système de reconnaissance vocale à partir d’un fichier audio pour vos besoins professionnels ou personnels.
Reconnaissance vocale à partir d’un fichier audio : Applications pratiques et avantages
La technologie de reconnaissance vocale fichier audio, ou de décryptage de la reconnaissance vocale à partir d’un fichier audio en ligne, démontre un progrès significatif. Elle ne se contente pas de transformer les enregistrements audio en un format textuel, mais améliore également de manière significative les processus de travail dans divers domaines. Examinons plus en détail les applications pratiques et les avantages de cette technologie.
Éducation. Dans les établissements d’enseignement, la reconnaissance vocale à partir d’un fichier audio est devenue une partie intégrante du processus d’apprentissage. Les enseignants l’utilisent pour transformer les cours audio en documents textuels, facilitant ainsi le processus d’assimilation de l’information pour les étudiants.
Journalisme. Les journalistes, en particulier ceux qui mènent des interviews, utilisent activement la reconnaissance vocale à partir d’un fichier audio. Cela les aide à transformer rapidement les interviews enregistrées en articles de texte.
Santé. Dans le secteur de la santé, la reconnaissance vocale à partir d’un fichier audio a également un impact énorme. Les médecins et le personnel médical utilisent cette technologie pour traduire les notes vocales en dossiers médicaux, gagnant du temps et améliorant la précision de la documentation médicale.
Entreprise. Dans le secteur des affaires, la reconnaissance vocale fichier audio montre également sa valeur. Elle est utilisée pour transcrire les appels au service clientèle, créer des rapports d’appels textuels et analyser les commentaires des clients.
Application de la loi. Dans l’application de la loi, la reconnaissance vocale fichier audio en ligne joue également un rôle important. Les enregistrements d’interrogatoires et les déclarations de témoins sont transformés en texte, aidant dans les enquêtes de cas et fournissant une résolution de problèmes plus rapide.
Marketing et RP. Dans le domaine du marketing et des RP, la reconnaissance vocale à partir d’un fichier audio sert d’outil pour extraire des informations importantes à partir de contenus audio et vidéo.
Podcasts et radio. Dans le monde des podcasts et de la radio, la reconnaissance vocale à partir d’un fichier audio permet la création de versions textuelles de contenus audio, améliorant ainsi son accessibilité.
Les principaux avantages de la technologie de reconnaissance vocale à partir d’un fichier audio sont l’efficacité, la précision et l’accessibilité de l’information. Stocker les enregistrements audio en format texte simplifie considérablement la recherche et l’analyse de l’information, permet un traitement plus rapide de grands volumes de données, et rend le contenu plus accessible pour les personnes ayant des problèmes d’audition ou celles qui préfèrent un format textuel.
Transformation des processus d’affaires avec la reconnaissance vocale à partir d’un fichier audio
La transformation des processus d’affaires grâce à la reconnaissance vocale à partir d’un fichier audio est devenue possible grâce aux technologies modernes. Les logiciels de reconnaissance vocale à partir d’un fichier audio, tels que SpeechFlow, utilisent des algorithmes et l’apprentissage automatique pour convertir la parole en format écrit.
Précision et vitesse. Les logiciels de reconnaissance vocale fichier audio permettent le traitement de gros volumes de données avec une grande précision. Cela réduit la probabilité d’erreurs, ce qui est essentiel dans les processus d’affaires.
Automatisation. L’utilisation de logiciels de reconnaissance vocale fichier audio automatise de nombreux processus qui nécessitaient auparavant l’intervention humaine. Cela libère des ressources et permet de se concentrer sur des aspects plus importants de l’entreprise.
Analyse de données. Les données textuelles sont plus faciles à analyser que l’audio. Convertir les données vocales en format texte permet aux entreprises d’identifier plus facilement les tendances et de recueillir des informations précieuses pour la prise de décisions.
Intégration avec d’autres systèmes. Les logiciels de reconnaissance vocale à partir d’un fichier audio peuvent être intégrés à d’autres systèmes d’entreprise, créant des flux de travail plus complexes et automatisés.
Augmentation de l’accessibilité. Les logiciels de reconnaissance vocale à partir d’un fichier audio rendent le contenu accessible aux personnes ayant des besoins spéciaux, améliorant l’inclusivité et élargissant l’audience de l’entreprise.
Les logiciels de reconnaissance vocale à partir d’un fichier audio sont un élément clé de l’optimisation des processus d’affaires. L’utilisation de cette technologie peut améliorer considérablement l’efficacité, réduire les coûts et rendre une entreprise plus compétitive sur le marché.
Reconnaissance vocale fichier audio dans la vie quotidienne
La technologie de reconnaissance vocale fichier audio devient de plus en plus importante dans la vie quotidienne, offrant commodité et facilité d’utilisation. Elle est facilement accessible via une gamme de services en ligne offrant de la reconnaissance vocale à partir d’un fichier audio en ligne.
La première chose qui vient à l’esprit est la possibilité de saisie vocale de notes et de rappels. Beaucoup d’entre nous parlent plus vite que nous n’écrivons. Grâce à cette technologie, vous pouvez facilement enregistrer des idées et des pensées par la voix, sans vous soucier de devoir les transcrire plus tard.
Pour ceux qui étudient des langues étrangères, la reconnaissance vocale à partir d’un fichier audio en ligne est un outil puissant. Avec cela, vous pouvez écouter du matériel audio en langue étrangère tout en voyant simultanément une transcription textuelle, simplifiant le processus de compréhension.
D’un point de vue sécurité, utiliser la reconnaissance vocale à partir d’un fichier audio en conduisant peut être très utile. Au lieu d’être distrait en tapant des messages texte, vous pouvez simplement les prononcer à voix haute, et la technologie les traduira en texte.
Il est également important de mentionner à quel point la reconnaissance vocale à partir d’un fichier audio en ligne est essentielle pour les personnes malentendantes. Grâce à la reconnaissance vocale fichier audio en ligne, ils ont la possibilité de percevoir du contenu audio, qui était auparavant indisponible.
En conclusion, il convient de noter que la lecture de texte se fait souvent plus rapidement et plus facilement que l’écoute d’audio. Ceci peut être particulièrement utile lors de la visualisation de longues conférences ou webinaires.
Ainsi, la technologie de reconnaissance vocale fichier audio en ligne joue un rôle significatif dans la vie quotidienne. Que ce soit pour l’apprentissage, le travail, ou la communication, elle rend les processus plus efficaces et accessibles à tous.
SpeechTexter
Présentation générale : SpeechTexter est une application gratuite de reconnaissance vocale à partir d’un fichier audio qui vous assiste dans la transcription de notes, documents, livres, rapports ou articles de blog en utilisant votre voix. Cette application comprend également une liste de commandes vocales personnalisables, permettant aux utilisateurs d’ajouter des signes de ponctuation, des phrases fréquemment utilisées, et certaines actions dans l’application (annuler, refaire, créer un nouveau paragraphe).
Architecture :
SpeechTexter utilise la technologie de reconnaissance vocale de Google pour convertir la parole en texte en temps réel. Cette technologie est prise en charge par le navigateur Chrome (pour les ordinateurs de bureau) et certains navigateurs sur Android OS. D’autres navigateurs n’ont pas encore implémenté la reconnaissance vocale.
Avantages :
- Reconnaissance vocale puissante en temps réel.
- Création de notes textuelles, emails, articles de blog, rapports, et plus encore.
- Commandes vocales personnalisables.
- Support pour plus de 70 langues.
Inconvénients :
- Ne supporte pas l’iPhone et l’iPad.
- Nécessite l’utilisation du navigateur Chrome pour une fonctionnalité complète.
Veuillez noter : aucun téléchargement, installation, ou inscription n’est nécessaire. Il suffit d’appuyer sur le bouton du microphone et de commencer à dicter.
Temi
Présentation générale :
Temi est un outil d’enregistrement vocal basé sur l’un des moteurs de reconnaissance vocale les plus précis au monde. Temi offre la possibilité de diffuser la reconnaissance vocale à partir d’un fichier audio en temps réel pendant l’enregistrement ! Stockez, recherchez et extrayez des informations utiles à partir de transcriptions synchronisées avec votre audio (des transcriptions sont fournies moyennant un petit frais par minute).
Architecture :
Temi offre un enregistrement vocal de haute qualité et une lecture. Il garantit une pause automatique pour les appels entrants et la reprise automatique de l’enregistrement si vous fermez l’application. De plus, Temi vous permet d’importer de l’audio à partir d’autres applications et de renommer les enregistrements.
Avantages :
- Sans publicité.
- Nombre illimité d’enregistrements.
- Enregistrement et lecture de haute qualité.
- Pause automatique pour les appels entrants.
- Possibilité de partager les enregistrements sans limitations.
- Importation de l’audio à partir d’autres applications.
Inconvénients :
- Actuellement, Temi ne transcrit que les fichiers audio et vidéo en anglais.
- Des frais sont facturés pour les transcriptions en fonction de la longueur de l’audio.
En conclusion, Temi est un outil puissant pour ceux qui recherchent une solution fiable pour l’enregistrement vocal et l’obtention de transcriptions avec une haute précision.

Transcribe Live
Présentation générale :
« Transcribe Live » est une application de premier plan dans le domaine de la « reconnaissance vocale à partir d’un fichier audio » conçue pour un usage professionnel. Elle est utilisée pour la transcription instantanée de réunions, d’entretiens, de notes, de conférences et de conversations en format texte, simplifiant le processus de documentation et d’analyse de données. L’utilisation de technologies de reconnaissance vocale permet une traduction instantanée des enregistrements audio en format texte.
Architecture :
Avec « Transcribe Live », vous pouvez enregistrer de l’audio en temps réel et voir votre discours converti en texte. Le logiciel a été développé en gardant à l’esprit la commodité de l’utilisateur, il permet donc un fonctionnement en mode arrière-plan avec l’écran éteint et fournit des horodatages pour chaque mot prononcé.
Avantages :
« Transcribe Live » a plusieurs avantages, dont :
- Transcription instantanée en plusieurs langues, dont l’arabe, l’anglais, le français, le japonais, le coréen, le chinois, le portugais et l’espagnol.
- Identification des différents locuteurs dans les transcriptions en anglais, espagnol et japonais.
- Capacité à partager rapidement et facilement les enregistrements audio et les transcriptions avec des collègues et des amis.
- Respect de la vie privée des utilisateurs – les données sont stockées uniquement sur votre appareil et ne sont pas transmises à des tiers.
Inconvénients :
Malgré sa variété de fonctionnalités, « Transcribe Live » a quelques inconvénients :
- L’application est uniquement disponible pour les utilisateurs d’iPhone et d’iPad ; il n’y a pas de versions pour Android et PC.
- Les abonnements à « Transcribe Live » sont renouvelés dans les 24 heures précédant la fin de la période en cours, et le prélèvement est déduit de votre compte iTunes.
« Transcribe Live » est un outil efficace et fiable dans le domaine de la « reconnaissance vocale fichier audio » qui répond aux besoins des utilisateurs modernes et fournit.
VoxRec
Présentation générale :
VoxRec est un dictaphone de haute technologie avec un service intégré de reconnaissance vocale à partir d’un fichier audio. Cette application est conçue à l’aide de l’intelligence artificielle pour convertir vos notes vocales en format texte.
Architecture :
VoxRec offre des fonctionnalités pour l’enregistrement audio, la transcription en direct, l’édition et la mise en forme du texte transcrit, l’envoi par e-mail des transcriptions, la personnalisation des dictionnaires, la recherche de mots-clés, et bien plus encore. Il prend également en charge l’enregistrement et la synchronisation avec l’Apple Watch, ainsi que l’intégration transparente avec les services cloud.
Avantages :
- Transcription instantanée : l’application fournit une transcription rapide et précise de la voix en texte en temps réel.
- Enregistrement de haute qualité : prend en charge l’enregistrement sur divers appareils et permet la sélection de la qualité audio.
- Édition et mise en forme : la possibilité d’éditer et de formater le texte directement dans l’application.
- Intégration au cloud : sauvegarde automatique de tous les enregistrements et transcriptions dans le service cloud de l’utilisateur.
- Multilingue : prend en charge la dictée et la transcription de la parole en texte dans 27 langues.
Inconvénients :
- Support de la plateforme : l’application n’est disponible que pour les utilisateurs d’iPhone, d’iPad et d’Apple Watch ; il n’y a pas de versions pour Android ou PC.
- Qualité de la transcription : la qualité de la transcription peut diminuer en présence de bruits de fond forts.
- Absence de ponctuation automatique : la ponctuation automatique peut ne pas être disponible dans toutes les langues.


Transcribe – Speech to Text
Présentation générale :
Transcribe est votre assistant personnel pour transcrire des notes vidéo et vocales en texte. L’application utilise des technologies d’intelligence artificielle qui vous permettent de recevoir instantanément des transcriptions de qualité et lisibles d’un simple clic.
Architecture :
Transcribe transcrit automatiquement toutes les notes vidéo ou vocales, en prenant en charge plus de 120 langues et dialectes. Vous pouvez importer des fichiers provenant d’autres applications et de DropBox, ainsi qu’exporter du texte brut vers votre application d’édition de texte préférée. Transcribe ne contient pas de publicités.
Avantages :
- Transcription automatique : Transcribe peut convertir automatiquement n’importe quelle note vidéo ou vocale en texte.
- Support linguistique : Prend en charge plus de 120 langues et dialectes.
- Intégration avec d’autres applications : Vous pouvez importer des fichiers provenant d’autres applications et de DropBox.
- Exportation de texte : La possibilité d’exporter du texte brut vers n’importe quelle application d’édition de texte.
- Pas de publicités : L’application ne contient pas de publicités, ce qui la rend plus agréable à utiliser.
Inconvénients :
- Disponibilité de la plateforme : Actuellement disponible uniquement pour iPhone, iPad, MacOS et la transcription en ligne de sites web. Il n’existe pas de version Android.
- Limitations de la version gratuite : La version gratuite offre seulement 15 minutes de transcription gratuite. Des fonctionnalités supplémentaires nécessitent un abonnement à Transcribe PRO.
- Renouvellement automatique de l’abonnement : L’abonnement est automatiquement renouvelé s’il n’est pas annulé dans les 24 heures précédant la fin de la période en cours.
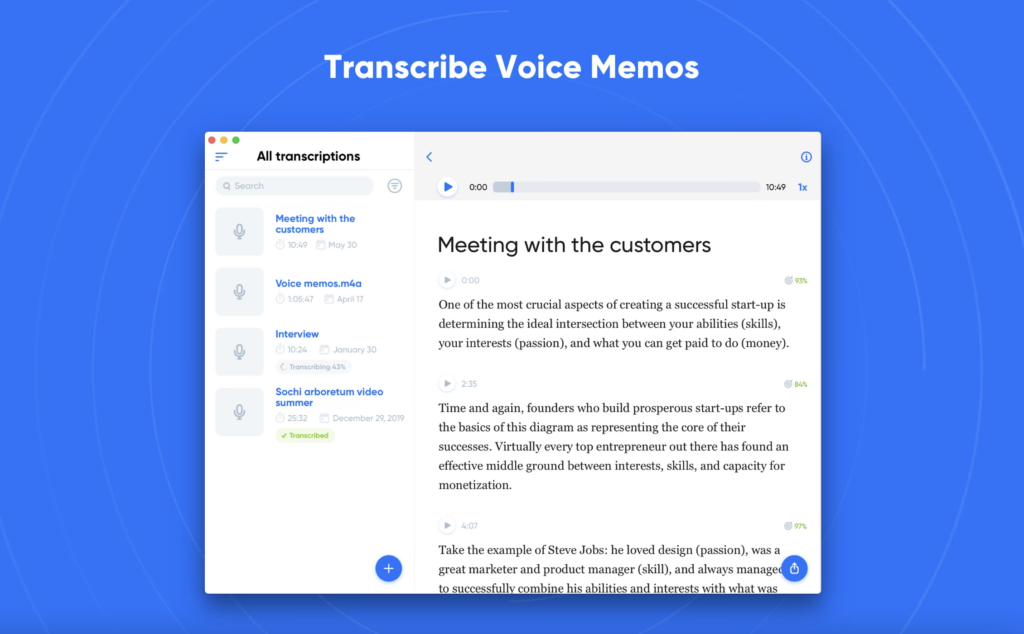
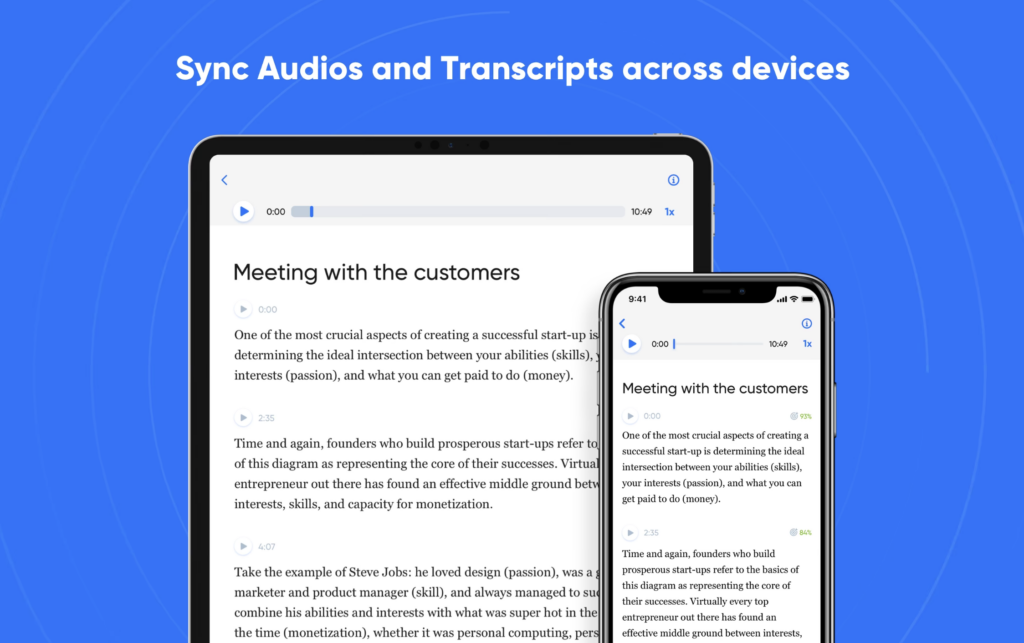
L’avenir des logiciels de reconnaissance vocale à partir d’un fichier audio : Un regard vers l’avenir
État actuel de la traduction audio en texte
L’avenir de la technologie audio en texte
Défis et problèmes possibles
Conclusion
Questions Fréquemment Posées sur l’Impact de la Technologie de Traduction Audio en Texte sur les Entreprises et la Vie Quotidienne
Question : Qu’est-ce que la « reconnaissance vocale à partir d’un fichier audio » ?
Question : Comment la « reconnaissance vocale fichier audio » peut-elle changer les affaires ?
Question : Comment la « reconnaissance vocale à partir d’un fichier audio » peut-elle changer la vie quotidienne ?
Question : Quels outils existent pour la « reconnaissance vocale à partir d’un fichier audio en ligne » ?
Question : Quels sont les inconvénients de la « reconnaissance vocale à partir d’un fichier audio » ?
Question : Qu’est-ce que la « reconnaissance vocale à partir d’un fichier audio » et comment cela fonctionne-t-il ?
Question : Quelles tendances futures peut-on attendre dans le domaine de la « reconnaissance vocale fichier audio » ?
Conclusion et Résumé : L’Impact de la Traduction Audio en Texte sur les Affaires et la Vie Quotidienne
En conclusion, on peut dire que la technologie de traduction audio en texte apporte déjà des changements significatifs aux affaires et à la vie quotidienne. Plus que jamais, les outils de traduction audio en texte facilitent le travail, améliorent les communications et ouvrent de nouvelles possibilités d’utilisation individuelle et collective.
La capacité de transformer l’audio en texte en temps réel ouvre des portes pour la communication mondiale, l’éducation et la communication d’entreprise. Elle facilite les barrières linguistiques et l’accessibilité, rendant le monde un peu plus connecté. Par ailleurs, avec la croissance des technologies d’intelligence artificielle et d’apprentissage automatique, l’avenir de ces outils semble encore plus prometteur.
En même temps, il est important de se rappeler des problèmes de confidentialité et de sécurité qui surgissent également avec le développement de ces technologies. L’utilisation responsable et le traitement des données, y compris les données audio, doivent rester une partie importante de la discussion sur l’avenir de la traduction audio en texte.
En conclusion, dans un monde où les données deviennent un atout de plus en plus précieux, la capacité de transformer rapidement et efficacement l’audio en texte est un outil clé pour le succès au 21ème siècle. Que ce soit pour accélérer le flux de travail, augmenter l’accessibilité de l’information, ou briser les barrières linguistiques, la traduction audio en texte apporte des avantages significatifs pour les affaires et la vie quotidienne.
Êtes-vous prêt à faire partie de la révolution de la traduction audio en texte ? Rejoignez des milliers d’utilisateurs satisfaits de SpeechFlow et transformez votre flux de travail. Cliquez ici pour vous inscrire et commencer à utiliser notre service innovant.
